Лекция VII. Восприятие речи
7.1. Видимая речь.
Наиболее объективным представлением акустического процесса речи является спектр звуковых колебаний – то есть состав тех обертонов и их интенсивности, из которых складывается музыкальный тон и из которых можно представить состоящим любой шумовой звук. Спектр речевого звука мы ранее изображали в виде рисунка, показывающего формантную структуру голоса. Существуют акустические приборы, позволяющие получать изображение спектра в процессе самого звучания (как теперь говорят – «в реальном масштабе времени»). Принцип действия таких приборов можно пояснить на примере струнного устройства таких музыкальных инструментов, как рояль или арфа. Основной частью этих инструментов является жесткая рама, на которой натянут
![]()
![]()
![]()
![]()
![]()
![]()

![]()
![]()
![]() Рис. 7.1. Арфа
Рис. 7.1. Арфа

многочисленный ряд струн в порядке высоты собственного тона
их колебаний. Когда рядом с таким устройством раздаётся достаточно громкий звук,
струнный стан (если струны не заглушены специальными подушками) отзывается
своими колебаниями. Струны приходят в движение (и начинают звучать) в той мере,
в которой раздавшийся звук соответствует частоте собственных колебаний каждой
струны. Размах (амплитуда) этих колебаний струн и представляет собой спектр
раздавшегося звука. Его можно изобразить в виде графика формантной структуры
(как мы делали ранее), где на горизонтальной оси будет указан тон (частота
собственных колебаний) соответствующей струны, а вдоль вертикальной оси будет
откладываться размах или энергия колебаний этой струны.
Частота
колебаний Рис.
7.2.

Этот спектр можно записать для каждого момента времени и изобразить на бумаге в виде отдельных временных срезов, расположенных друг за другом, где энергия будет изображаться не расстоянием вдоль вертикальной оси, а густотой положенной краски. Тогда мы получим ленту временных срезов спектра, где полосы густой краски будут изображать диапазоны частот с концентрацией энергии колебаний, то есть форманты звука. Перестройка этих полос наглядно изображает динамику акустического процесса. Такое представление речевого процесса называется «видимая речь». При современной технике она получается не механическими устройствами музыкальных инструментов, а электронными приборами – спектроанализаторами. Соединённый с вычислительной техникой спектроанализатор речи может зафиксировать спектр звуков и показать его на экране или изобразить на бумаге для изучения. Зафиксированный на графике спектр называется спектрограммой, а прибор, получающий её – спектрограф.
Рис. 7.3. Частота

![]()
![]()
![]()


![]()
Основной
тон
конец звука
Динамическая спектрограмма, показывающая для каждого момента речи громкости (мощности) составляющих звук тонов даёт объективное параметрическое описание акустического процесса, альтернативное тому артикуляционному описанию, которое мы рассматривали ранее. Эти два описания могут быть приведены в соответствие друг с другом, при котором определённым артикуляционным признакам соответствуют определённые свойства спектра. Так гласным соответствует наличие энергичных колебаний основного тона и формантное распределение энергии звука по дискретным (отдельным) частотам обертонов, кратным основному тону. Так звуку [a] соответствует следующая спектрограмма {Рис.7.4} Пусть частота основного тона будет 100 гц. Тогда на этой области спектрограммы будет сильное зачернение, показывающее высокоэнергичные колебания. Почти такие же зачернения отличают частоты первой и второй формант в области 500 и 1000 гц. Менее яркие полосы будут отличать более высокие форманты. Обертоны, не входящие в форманты будут показаны слабыми, почти незаметными линиями на всех частотах, кратных 100. Для [a] характерно близкое расположение F1 и F2 . Это компактный гласный.
Для более узкого звука [ε] частота F1 понижается, а F2 повышается, составляя примерно 400 и 1500 герц. Звуку [i] соответствуют ещё более удалённые частоты первых формант: 200 и 2000 гц. Это - диффузное расположение формант, характерное для узких передних гласных, которые с акустической стороны описываются как диффузные.
Рис. 7.4.
50
100
200
400
800
1500
3000
6000
12000 гц
Частота

[a]
![]()
[e]
![]()
![]()
![]()

![]()
[i]
![]()
![]()
[o]
![]() [u]
[u]

[x]
Ухта
смычка
[t]
![]()
![]() взрыв
взрыв
![]()
![]()
![]()
![]()
![]() [a]
[a]
Включение в работу губ приводит к понижению частоты всех формант и спектр приобретает бемольный характер с усилением низких тонов. Так для звука [o] первая форманта соответствует звуку среднего подъёма и равна как и у [ε] 400 гц при частоте второй форманты около 800 гц. Ещё ниже (бемольнее) расположены форманты звука [u] – 200 и 600 гц.
Переход от гласного к шумному согласному характеризуется прежде всего прекращением периодических колебаний основного тона и размыванием полос, соответствующих обертонам – кратным значениям основного тона. При компактном сосредоточении энергии шумовых колебаний в области относительно низких частот получим звук [x]. Сочетание [u] и [x] даёт слово «Ух».
Смыкание ртового тракта приводит к прекращению звучания. На спектрограмме образуется разрыв изображения, предваряемый сдвигом энергии шума в зависимости от места образования смычки. При переднеязычной смычке энергия перетекает в область высоких частот из-за резонанса малого переднего объёма. Длительность смычных гласных примерно равна длительности звучания других фонем. Разрыв переднеязычной смычки даёт взрывной краткий шум с энергией по всему диапазону частот, сопровождаемый непродолжительным фрикативным шумом на частотах, характерных для места образования смычки. И если вслед за взрывом появляется музыкальный тон с формантами в районе 400 и 1000 гц, то получим звук [a] и слово «Ухта» (есть такой город на Севере).
Реальные картины видимой речи для различных слов, звуков и предложений можно посмотреть, например, в недавно вышедшей прекрасной книге С. В. Кодзасова и О. Ф. Кривновой «Общая фонетика» (М.: РГГУ, 2001).
На основе анализа картин видимой речи можно научиться визуально распознавать произносимые слова. Признаки, по которым происходит такое распознавание звуков, служат основой алгоритмов автоматической обработки текущих спектральных срезов средствами вычислительной техники. При этом выявляются и анализируются такие параметры, как наличие и частота основного тона, формантная структура, динамика движения энергии по шкале частот, мощность шумовой составляющей. В результате, звучащая речь представляется потоком параметров, подобным рассмотренному сейчас нами представлению речи потоком артикуляционных данных. Сейчас разработаны и практически используются технологии, позволяющие довольно надёжно распознавать все фонемы и понимать слова в речи, произносимой достаточно отчётливо.
7.2. Слышимая речь
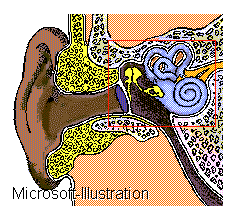
Теперь настало время разобраться, как воспринимается речь ухом человека. Основным органом слуха является некое подобие того же струнного устройства арфы, выполненное в форме рупорообразной трубы, завёрнутой в спираль, которое помещается во внутреннем ухе и называется улиткой.

![]()
![]() .
.
Стремечко
Рис. 7.5
Улитка заполнена упругой жидкостью (наподобие студня),
которая приходит в колебания под действием движений барабанной перепонки в ухе,
воспринимающей давление звуковой волны и передающей свои движения на рупор
улитки через систему трёх косточек. Непосредственно на улитку давит косточка в
форме стремени – стремечко.
Расположена улитка во внутреннем ухе и хорошо видна на красочном рисунке уха в разрезе
(Рис. 7.6).
{kind=link}
Аналогично струнам арфы, разные участки улитки от внешнего воздействия приходят в колебательное движение со своей собственной частотой, которая определяется упругостью жидкости и формой улитки. Но в отличие от арфы, наиболее жёсткая часть улитки – то, где её сечение максимально, возле основания (рупора), а наиболее податливая часть – это тонкая закрученная вершина. Так что при воздействии звука определённой частоты он заставляет колебаться желеобразное тело улитки в некоторой вполне определённой области, определяемой этой частотой. При поступлении в ухо сложного звукового колебания движение улитки отразят состав его обертонов распределением интенсивности своих колебаний по длине спирали. Тем самым улитка отразит обертонную и формантную структуру распределением возбуждений в разных местах. Движения улитки воспринимаются чувствительными нервными клетками, так называемыми, волосковыми клетками, которые расположены в ряд вдоль одного края улитки, называемый кортиевым органом. Каждая волосковая клетка (их всего около 20 000) реагирует на давление колеблющейся мембраны улитки и при каждом нажатии посылает нервные импульсы в головной мозг для обработки. Как именно происходит эта обработка, науке пока не известно, хотя многие детали и удалось уже исследовать. Во всяком случае, из рассмотрения устройства улитки ясно, что в мозг поступает подробная информация о формантной структуре звука. И центральная нервная система имеет возможность реализовать определённые алгоритмы распознавания звуков речи по признакам формантной структуры – частотам формант и характеру их изменений. Это происходит аналогично тому, как мы можем анализировать зрительно или приборно фигуры видимой речи и делать заключения о движении органов артикуляции и составе артикуляционных признаков звука при их производстве.
Таким образом, мы имеем три последовательных акустических представления звучащей речи, которые переходят одно в другое и находятся в регулярном соответствии друг с другом:
- артикуляторные (двигательные) параметры;
- физические параметры звука в «видимой речи»;
- параметры физиологического возбуждения в слуховой системе («слышимая речь»).
Два последних представления в существенной части сводятся к формантной структуре звука. Для слова «свет», артикуляторное представление которого мы рассматривали на прошлой лекции, можно дать и формантное представление в картине видимой речи.
Сначала появляется шум, характеризующийся распределением энергии по всем частотам, преимущественно высоким – звук [s]. Затем шум убывает и появляются не слишком энергичные колебания музыкального тона – где-то около частоты 100 Гц в зависимости от высоты голоса. Они сопровождаются первыми обертонами (200 Гц) и появлением высокочастотной форманты, свойственной мягким звукам. Это звук [v]. Далее высокочастотная форманта снижается, а от первого обертона отделяется низкочастотная форманта, и они принимают значения, свойственные звуку [ε] – 400 и 1500 Гц. С наступлением смычки языка для звука [t] исчезают периодические колебания основного тона вместе с формантами, настаёт пауза. При размыкании преграды взрывной звук изображается на спектрограмме кратковременным появлением энергии на всех частотах, которое сопровождается слабым шумом придыхания с энергией в области средних частот.
Частота формант,
Гц
![]()
![]()
Шум Взрыв F2
 12000
12000
6000

![]()
![]()
![]() 3000
3000
Придыхание
![]() 1500
1500
F1
![]() 800
800
 400
400
![]() 200
200
Основной
тон
![]() 100
100
![]() 50
50
[s
v’
e
t]
Время
Рис. 7.7
7.3. Фонемное речевосприятие.
Но при слушании человек не осознаёт физических параметров речи, не чувствует форматную структуру, а сразу понимает смысл речи. Так что восприятие речевых звуков является лишь подчинённым моментом речевосприятия. Цель речевосприятия определить не звук, а смысл. Поэтому слуховому органу не нужно трудиться, расходовать энергию и другие биологические ресурсы для различения разных звуков до тех пор, пока это различие звуков не оказывается существенным для различия смыслов. Смысл первичен – звук вторичен. Чтобы понять, какие мы звуки должны различать, нужно определить, какие смыслы нам следует различать. Так, если мы прислушиваемся в тёмном помещении, чтобы определить, есть ли в нём кто-нибудь, то любой звук для нас будет иметь один и тот же смысл. И в этой ситуации нам вовсе не нужно различать звуки, их нужно только ощущать.
В ситуации речевого общения нам нужно именно различать смыслы путём различения звуков. Смыслы в языке, как мы уже говорили на начальных лекциях, выражаются языковыми знаками, обозначающими отдельные явления и предметы действительности – словами. Это единицы уже не звукового яруса языка, а лексического. Единицы лексического яруса постоянно хранятся в языковой памяти человека и у человека имеются механизмы опознавания и различения этих знаков (слов) по звукам речи. Так что для того, чтобы понять, какие звуки мы должны различать, нужно задать список слов, существующих в языке. Далее нужно изучить параметры звуковых процессов, реализующих эти слова в речи, выделить те признаки этих процессов, которые отличают одно слово от другого. Эти признаки и будут теми «звуками», которые мы воспринимаем в процессе слушания. Эти признаки и будут фонемами, то есть стандартными единицами фонетического яруса, постоянно присутствующим в языковом памяти в качестве звуковых эталонов восприятия речи.
Как происходит выявление фонем, рассмотрим на искусственном примере. Пусть в нашем языке имеются только следующие слова: свет, свит, свят, сват. Для них у нас имеется артикуляторное и спектральное представления во всех подробностях. Спрашивается, какие должны быть в языке фонемы, чтобы различать эти (и только эти) слова? Среди отрезков звучания этих слов есть более сходные друг с другом и менее сходные. Наибольшее различие наблюдается, видимо, между открытыми гласными [a] и сегментом смычки [t], который реализуется просто беззвучной паузой. Эти сегменты очевидно следует отнести к разным фонемам. Сегмент [a] действительно отличает одно из этих слов ото всех других. Это действительная фонема, в то время, как сегмент [t] присутствует в каждом слове, не различает их, и поэтому может быть проигнорирован при различении заданных слов, то есть не является фонемой. Аналогично, не являются фонемами совпадающие начальные и конечные шумовые участки этих слов. Фонеме /a/ в других словах противопоставлены звуковые сегменты [i] и [ε]. (Фонемы обычно принято обозначать транскрипционными знаками в косых скобках). Однако в слове «свят» присутствует тот же сегмент [a], что и в слове «сват». Они отличаются другими признаками: мягкостью [v] и переходным участком от [v] к [a]. Так, что эту последовательность сегментов следует признать отдельными фонемами. В фонему /vЪ/ входит твердый звук [v] (без высокочастотной форманты в спектре и без переднеязычной артикуляции в произношении) и переходной ы-образный участок гласного [a]. В фонему /vЬ/ входит мягкий [v’] (с высокочастотной формантой около 1500 Гц и соответствующей переднеязычной артикуляцией) и переходной и-образный участок гласного. Этот фрагмент звучания совпадает в целом у всех трёх слов, кроме слова «сват». Итак, мы получили следующее фонемное представление этих слов в нашей модельной ситуации:
/vЬ i/,
/vЬ ε/, /vЬ a/,
/vЪ a/
Имеем 4 фонемы для различения четырёх слов.
Таким образом, в памяти нашего модельного языкового механизма должны храниться:
1) звуковые эталоны 4-х фонем;
2) 4 последовательности из 2-х фонем для представления 4-х знаков.
Но если у нас 4 фонемы и 4 слова, то зачем каждое слово записывать двумя фонемами? Нельзя ли каждое слово опознавать по одной фонеме? Оказывается можно. Нужно лишь в качестве гласных фонем принять суммарный звуковой отрезок, включающий переходные участки начала гласного. Тогда в слове «сват» мы будем иметь фонему /Ъa/ с ы-образным началом, а в слове «свят» – фонему /Ьa/ с и-образным началом. При этом отличием твёрдого [v] от мягкого [v’], которое акустически совершенно незначительно, можно пренебречь, потому что мы и так уже отличили эти два слова, и незачем напрягать дальше слух, чтобы уловить тонкие параметры других сегментов. Их лучше вообще игнорировать, сосредоточившись на восприятии наиболее громких, ясных участков, представленных гласными. Тогда нам достаточно иметь четыре фонемы гласных /i/, /ε/, /Ьa/, /Ъa/, которые и будут идентифицировать и отличать эти слова в соответствии с тем, как это делает орфография: и-е-я-а. Согласные в этой модели теряют свой фонемный статус, становясь просто бессодержательными призвуками гласных. Новая фонологическая модель предлагает хранение в языковой памяти вдвое меньше данных для представления заданного набора знаков: каждый из них опознаётся не по двум, а только по одной фонеме.
В реальном языке, конечно, не четыре слова, а скорее 400 тысяч слов, для распознавания которых требуется больше фонем и вопрос об объёме памяти, необходимой для хранения этих данных приобретает определяющее значение. Аналогично проделанной нами процедуры анализа звуковых сходств и различий этих 400 тысяч русских слов можно прийти к выделению реальных фонем русского языка, которых оказывается примерно 40 единиц, точное число которых зависит от некоторых дополнительных соображений. Мастерство фонемного анализа состоит в том, чтобы анализ этих 400 тысяч слов организовать таким образом, чтобы он скорейшим путём привёл к конечному результату.
Процедуру фонемного анализа можно изложить в виде строгого алгоритма и осуществить средствами вычислительной техники на материале различных наборов реально произносимых слов. Один из вариантов алгоритма исходит из предположения, что набор анализируемых слов задан в виде последовательностей мельчайших акустических сегментов с объективно измеренными акустическими или артикуляторными параметрами. Построение набора фонем достигается последовательным выполнением двух операций: 1) склеивание соседних звуковых сегментов и 2) отождествление (отнесение к одной фонеме) несоседних сегментов. Обе операции выполняются для тех сегментов, раздельное рассмотрение (различение) которых не требуется для различения хотя бы одной пары слов. Очерёдность объединения (склеивания и отождествления) сегментов производится в порядке их акустического сходства. Очевидно: чем ближе друг к другу звучание сегментов речи, тем труднее их отличать друг от друга и тем способнее их относить к одному функциональному классу звуков – к одной фонеме. Близость звуков может быть измерена как сходство их характеристик. Или наоборот на множестве звуков может быть определена мера расстояния между звуками, например, как сумма разностей параметров по всем строкам артикуляционной таблицы или всем частотам спектра (по всем сторонам видимой речи). Могут быть заданы и другие мерв расстояния. Если мы желаем, чтобы наше построение отражало в максимальной степени явления реального языка, мы должны ввести меру близости звуков с учётом физиологических способностей слуха различать звуки. Такой общепринятой шкалы пока ещё нет. И указанную процедуру пока ещё никто не реализовывал для реальных языковых данных. Частичные эксперименты, однако, дали интересные результату.
Если в качестве исходного материала взять артикуляционное представление десяти чисел 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, то при вполне разумной мере расстояния компьютерная программа выявляет системы всего лишь из двух фонем: в одну фонему собираются, главным образом, сегменты ударных гласных, а в другую – все остальные сегменты, то есть выявляется ритмическая структура речи. (Этот набор знаков может иметь практическое значение для ввода данных в компьютер с голоса). Когда в этот словарь были добавлены наименования математических и машинных операций (всего 30 слов), программа выделила три фонемы: губная артикуляция, ртовая гласная и ртовая согласная. При дополнении словаря названиями всех букв русского и латинского алфавитов выявилось 6 фонем: одна общая согласная и пять гласных обычной русской фонетики. Наконец, словарь из 200 трёхсегментных произнесений русских простейших слогов (па, ба, та, да, …) привёл к почти обычной русской системе фонем, где отсутствовало только противопоставление шипящих свистящим (ж, з и ш, с были объединены в одну фонему), а также твёрдых мягким согласным. Такая последовательность развития фонемной системы в зависимости от объёма словаря соответствует известным фактам становления детской речи, когда развитие произносительных способностей связано с числом употребляемых ребёнком слов. Именно: ребёнок воспринимает ритмическую структуру речи, когда ещё никаких слов ни произносить ни понимать не может; первыми воспринимаемыми различиями звуков речи для ребёнка является различие губных и негубных звуков; различия твёрдых и мягких, шипящих и свистящих являются самыми трудными и осваиваются ребёнком иногда только к школьному возрасту.